Report 3 — Final Documentation & Analysis
Table of Contents
- Report 3 — Final Documentation & Analysis
- Table of Contents
- 1. Graphical Abstract
- 2. Algorithm
- 3. Benchmarking & Results
- 4. Ethical Impact Statement
- 5. Custom Module Code Links
- 6. Individual Contribution & Audit Appendix
1. Graphical Abstract
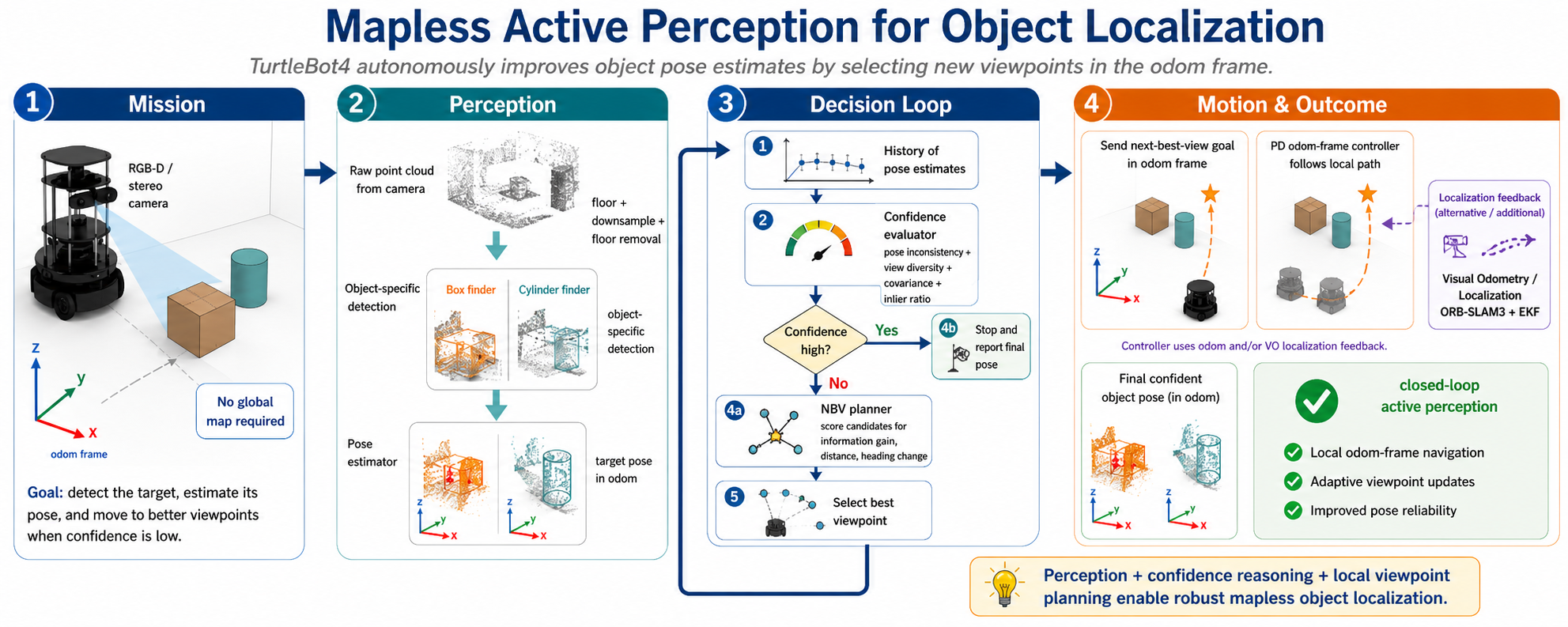
Figure 1.1. Graphical abstract summarizing the project mission, core perception-and-planning pipeline, and final mission outcome.
1.1 Project Mission
This project addresses the problem of localizing a target object using a mobile robot in an indoor environment without relying on a pre-built map. The robot observes the scene with onboard vision sensors, estimates the object pose in its local odometry frame, and evaluates whether that estimate is reliable enough for use. When confidence is low, the robot autonomously moves to a better nearby viewpoint and repeats the estimation process. The mission objective is to achieve more reliable object localization through closed-loop active perception rather than a single static observation
2. Algorithm
This section presents the algorithmic design rationale and execution logic of the custom modules and ROS 2 nodes used in the system. Although Report 2 outlined the main components and their core functions, this section examines them in greater detail, with emphasis on internal data flow, decision-making logic, and the way the modules interact to support active perception.
2.1 System Components and Their Interactions
2.1.1 Perception Module
The perception module structure and node-level connectivity were introduced in Report 2. In this report, the emphasis is on the final implementation logic and on the role of perception within the active perception loop. The module consists of the object-specific detection nodes (cylinder_finder.py and box_finder.py) together with the downstream pose_estimator.py node, which converts segmented target observations into pose estimates in the planning frame (odom).
Both detection nodes follow a common preprocessing pipeline based on spatial filtering, voxel downsampling, and floor removal. After that, each node applies object-specific reasoning. The final box finder differs from the earlier design outlined in Report 2. Rather than relying on a PCA-only interpretation of the segmented object, the implemented node first filters candidate points using a brown color model appropriate for cardboard-like box surfaces, then forms Euclidean clusters, and finally fits an upright oriented box by analyzing the horizontal footprint and vertical extent of each candidate cluster. Geometric constraints on dimensions and support size are used to reject implausible hypotheses, and the best valid cluster is selected as the box target. This change was introduced to make the final box detection stage more object-specific, since the earlier PCA-only approach did not provide sufficiently reliable detection performance
The segmented target cloud is then passed to the pose estimator, which computes the target centroid and dominant horizontal orientation, transforms the estimate into the odom frame, and publishes both the final pose and a pose-estimate sample for downstream confidence evaluation. In this way, the perception module provides the geometric target information required by the rest of the active perception system.
2.1.2 Planning Module
The planning module structure and its node-level role within the active perception loop were already described in Report 2. In the final system, the implementation logic of this module remained largely unchanged, with the confidence evaluator using a simplified four-term scoring scheme. The module consists of confidence_evaluator.py and nbv_planner.py, which together determine whether the current target estimate is sufficiently reliable or whether an additional viewpoint should be planned.
The confidence_evaluator.py node receives a recent history of pose-estimate samples and computes a confidence score from four quantities: positional variance, yaw variance, mean point count, and mean anisotropy ratio. These terms are combined into a single score that determines whether the robot should stop or continue the active perception process.
If the confidence threshold is not reached, the nbv_planner.py node generates candidate viewpoints around the current target estimate in the planning frame and scores them according to radius error, travel distance, and heading change. The best candidate is returned as the next-best-view goal, while marker outputs are published for visualization in RViz.
Together, these two nodes provide the decision-making layer that closes the active perception loop by determining whether the current estimate is sufficient or whether a new observation pose is required.
2.1.3 Visual Odometry or Estimation & Localization Module, ORB-SLAM3 + EKF
This section documents the localization module contribution based on ORB-SLAM3 stereo visual odometry integrated with EKF fusion.
Camera Used in ORB-SLAM Pipeline
The ORB-SLAM3 node uses the TurtleBot4 OAK-D stereo camera pair as its primary localization sensor:
- Left camera image topic:
/oakd/left/image_raw - Right camera image topic:
/oakd/right/image_raw - Left camera calibration topic:
/oakd/left/camera_info - Right camera calibration topic:
/oakd/right/camera_info
Stereo intrinsics and baseline are consumed through calibration/configuration parameters (fx, fy, cx, cy, image size, and baseline term such as Camera.bf) so that feature correspondences can be triangulated at metric scale.
How ORB-SLAM3 Works in This Project
ORB-SLAM3 estimates the camera pose by repeatedly solving a geometric consistency problem between image observations and a 3D map.
%%{init: {"themeVariables": {"fontSize": "20px"}, "flowchart": {"nodeSpacing": 45, "rankSpacing": 65}}}%%
flowchart TB
A["Stereo Images"] --> B["ORB Features"]
B --> C["Stereo + Temporal Matching"]
C --> D["Depth from Disparity"]
D --> E["Pose Optimization"]
E --> F["Publish VO Pose/Odom"]
F --> G["EKF Fusion"]
The Mermaid pipeline above can be explained as: ORB-SLAM3 computes a camera trajectory from stereo images, and this project publishes that trajectory as VO odometry/path.
In orb_vo_node.py, each synchronized stereo pair is sent to:
where T_cw^(k) is the camera pose returned by the backend at frame k. The node first inverts it to get camera pose in the ORB reference frame:
Then this trajectory is aligned to odom (startup anchoring) before publishing: \(\mathbf{T}_{odom,c}^{(k)} = \mathbf{T}_{cw}\,\mathbf{T}_{orb,c}^{(k)}\)
Both orb and odom are local startup-referenced frames (no global map frame is used).
The aligned local pose is transformed into robot planar motion and published as /orb_slam/vo_odom, while the full history is appended to /orb_slam/vo_path.
Block A: Stereo Images
Input at frame k: rectified stereo pair (I_L^k, I_R^k). Rectification enforces epipolar alignment:
Fundamentally, this means a match for a left pixel is searched along one row (the u-axis), not over a full 2D area.
Simple rectification math (step-by-step):
-
Start with raw left/right pixels and remove lens distortion using calibration: \(x_u = \text{undistort}(x_d; K, D)\)
-
Rotate both camera views into a common virtual stereo frame: \(x'_{L}=R_L x_{uL},\qquad x'_{R}=R_R x_{uR}\)
-
Reproject with rectified camera models: \(\tilde{u}_L=P_L X,\qquad \tilde{u}_R=P_R X\)
-
Choose
(R_L, R_R, P_L, P_R)so corresponding points land on the same row: \(v_L \approx v_R\) -
Then disparity is horizontal only: \(d = u_L-u_R,\qquad Z=\frac{f_x b}{d}\)
Parameter meaning:
u, v: pixel column and rowK: camera intrinsics(f_x, f_y, c_x, c_y)D: distortion coefficientsR_L, R_R: rectification rotationsP_L, P_R: rectified projection matricesb: stereo baselined: disparity
Calibration source in this implementation:
- Monocular calibration for each camera (left and right) comes from each
CameraInfomessage (K,D,R,Pfields). - Stereo calibration (left-to-right relationship) is also taken from the paired
CameraInfomessages, including baseline from the projection matrices. - In this project, these are read from
/robot_10/oakd/left/camera_infoand/robot_10/oakd/right/camera_info.
Block B: ORB Features
ORB feature extraction in this project does four things:
-
Build a multi-scale image pyramid (so features are found at different sizes): \(I^{(\ell)}(x,y)=I(x/s^\ell,\;y/s^\ell),\quad \ell=0,\dots,L-1\) where
sisORBextractor.scaleFactorandLisORBextractor.nLevels. Here,xis the horizontal pixel coordinate (column),yis the vertical pixel coordinate (row), andellis the pyramid level index. -
Detect FAST corners (good trackable points) at each level. FAST tests intensity change around each candidate pixel
p. A pixel is marked as a corner if enough contiguous pixels on a small circle are much brighter or darker than the center: \(I(q)\ge I(p)+t \quad \text{or} \quad I(q)\le I(p)-t\) wheretis the FAST threshold (ORBextractor.iniThFAST, with fallbackORBextractor.minThFASTin low-texture regions). -
Assign an orientation to each keypoint: \(\theta=\operatorname{atan2}(m_{01},m_{10})\) Here,
thetais the keypoint orientation angle,m10is the first-order intensity moment along the horizontal direction, andm01is the first-order intensity moment along the vertical direction in the local keypoint patch. This gives a dominant local direction, so the same point can still match after camera rotation. -
Build a binary descriptor by comparing pairs of pixel intensities in the oriented patch: \(b_m= \begin{cases} 1,& I(\mathbf{p}+\mathbf{a}_m)<I(\mathbf{p}+\mathbf{b}_m)\\ 0,& \text{otherwise} \end{cases}\) Parameter meaning in this test:
p: keypoint center pixel location in the current image level.I(.): image intensity function (pixel brightness value at a location).a_m, b_m: predefined offset vectors for comparison pairm, rotated by the keypoint orientation.b_m: output bit of comparisonm(1if the first sampled pixel is darker, else0).M: total number of binary comparisons used to form one descriptor. All bits are stacked into one descriptor vectordwith binary entries (0/1) and lengthM.
Final output per feature is: \((u,v,\theta,\mathbf{d})\) which means pixel location, orientation, and binary signature used for matching.
Block C: Stereo + Temporal Matching
Flow from Block B: each feature now has (u, v, theta, d) where d is a binary descriptor.
This block matches those descriptors in two ways:
- Left-right at same time
k(stereo match) -> needed for disparity/depth. - Frame
k-1to framek(temporal match) -> needed for motion tracking.
Descriptor similarity is measured by Hamming distance: \(d_H(\mathbf{d}_i,\mathbf{d}_j)=\sum_m \mathbf{1}[d_{i,m}\oplus d_{j,m}]\)
For each feature, ORB picks the best match with minimum distance: \(j^*=\arg\min_j d_H(\mathbf{d}_i,\mathbf{d}_j)\)
Then geometric checks reject bad matches (for stereo, row consistency after rectification; for temporal, motion consistency).
Small Hamming distance + geometric consistency means likely same physical 3D point.
Block D: Depth from Disparity
From stereo matches in Block C, disparity is: \(d=u_L-u_R\)
Depth is then computed by: \(Z=\frac{f_x b}{d}\)
Back-projection to 3D camera coordinates: \(X=\frac{(u-c_x)Z}{f_x},\qquad Y=\frac{(v-c_y)Z}{f_y}\)
So Block C gives valid stereo correspondences, and Block D converts them to metric 3D points.
Block E: Pose Optimization
Now combine:
- 3D points from Block D
- 2D observations in the current image
The camera pose T_k is estimated by minimizing reprojection error:
Interpretation in simple terms:
- Guess a pose.
- Project each 3D point into the image.
- Measure pixel error to where it was actually observed.
- Update pose to reduce total error.
This is the core VO step that produces the camera trajectory.
Block F: Publish VO Pose/Odom
After ORB-SLAM3 returns pose, the node aligns trajectory origin to wheel odometry at startup and publishes:
/orb_slam/vo_odom(current pose)/orb_slam/vo_path(trajectory history)
If ((x_o,y_o,\psi_o)) is startup odom and ((\Delta x,\Delta y)) is relative VO displacement, planar alignment is:
\[\begin{bmatrix} x\\y \end{bmatrix} = \begin{bmatrix} x_o\\y_o \end{bmatrix} + \begin{bmatrix} \cos\psi_o & -\sin\psi_o\\ \sin\psi_o & \cos\psi_o \end{bmatrix} \begin{bmatrix} \Delta x\\\Delta y \end{bmatrix}.\]This converts relative VO displacement into the odom frame used by the robot stack.
Block G: EKF Fusion
EKF fusion is optional integration stage for smoother localization. In this project report, VO path generation is produced directly by ORB-SLAM3 output; EKF is the downstream fusion layer when enabled. EKF sensor fusion was implemented but not calibrated . Final fused path is the average of VO and odom.
ORB-SLAM3 Features and Parameters Used
The ORB-SLAM3 configuration relies on the standard ORB feature extractor and stereo parameters:
ORBextractor.nFeatures: target number of features extracted per frame.ORBextractor.scaleFactor: image pyramid scaling between levels.ORBextractor.nLevels: number of pyramid levels for multi-scale matching.ORBextractor.iniThFAST: initial FAST threshold for keypoint detection.ORBextractor.minThFAST: fallback FAST threshold in low-texture regions.Camera.fps: expected image frame rate for timing consistency.ThDepth/stereo depth threshold terms: constrain valid stereo depth range.
Practically, these parameters control the accuracy/robustness trade-off: higher feature counts and tuned FAST thresholds improve tracking in texture-limited indoor scenes but increase compute load.
2.1.4 Navigation, Control, Actuation Module
The navigation and actuation role of the system was initially intended to be handled through Nav2, as discussed in Report 2. In the final implementation, however, Nav2 was replaced by a lightweight local controller implemented in odom_controller.py. This change was made because the final system operates without a global map and expresses all perception and planning outputs directly in the odom frame. Since Nav2 typically assumes a map-based navigation setup, it was not well aligned with the final local active perception pipeline.
An alternative attempt was made to use SLAM Toolbox in order to provide the mapping layer required for Nav2, but this integration was not brought to a stable operational state during the project. For this reason, the final system adopted a simpler local-control formulation that directly drives the TurtleBot4 to a goal pose in the odom frame.
The odom_controller.py node subscribes to an odom-frame navigation goal and the robot odometry feedback ( either robot odom or visual odometry), then publishes velocity commands to drive the robot toward the requested viewpoint. The controller uses proportional control for linear motion and PD control for heading correction, with bounded linear and angular velocities, a rotate-in-place mode for large heading errors, and separate tolerances for final position and yaw convergence. In this way, the module provides the final execution link between the viewpoint selected by the planner and the physical robot motion required to acquire the next observation.
2.1.5 Orchestrator
The orchestrator structure was already introduced in Report 2, and its core role remained unchanged in the final system. Its main responsibility is to connect the perception, planning, and motion-execution modules into a closed-loop active perception process. In the final implementation, this role was extended to include the local navigation executor: once a next-best-view pose is selected, the orchestrator publishes the corresponding odom-frame goal and waits for the navigation status before resuming perception.
Operationally, the orchestrator stores a bounded history of pose-estimate samples, waits until a minimum history length is available, calls the confidence-evaluation service, and either terminates the active perception loop or requests a next-best-view from the planner. If a new viewpoint is required, the selected goal is sent to the local controller, and the orchestrator returns to the observation state after navigation completes successfully. This makes the orchestrator the supervisory logic that manages state transitions between observation, evaluation, replanning, and motion execution.
Let the robot pose in the planning frame be
\[\mathbf{x}_k = \begin{bmatrix} x_k \\ y_k \\ \theta_k \end{bmatrix},\]and let the target pose estimate at step (k) be
\[\hat{\mathbf{o}}_k = \begin{bmatrix} \hat{x}_k \\ \hat{y}_k \\ \hat{\psi}_k \end{bmatrix}.\]Let the recent history of pose-estimate samples be
\[\mathcal{H}_k = \{s_1, \dots, s_N\},\]where each sample contains a pose estimate, the number of points in the segmented target cloud, and the anisotropy ratio returned by the pose-estimation stage. Over this history window, the confidence evaluator computes the position variance, the yaw variance, the mean point count, and the mean anisotropy ratio.
\[\sigma_p^2 = \frac{1}{N}\sum_{i=1}^{N} \left\| \begin{bmatrix} x_i \\ y_i \end{bmatrix} - \begin{bmatrix} \bar{x} \\ \bar{y} \end{bmatrix} \right\|^2,\] \[\sigma_\psi^2 = \frac{1}{N}\sum_{i=1}^{N} \operatorname{wrap}(\psi_i-\bar{\psi})^2,\] \[\bar{n} = \frac{1}{N}\sum_{i=1}^{N} n_i, \qquad \bar{a} = \frac{1}{N}\sum_{i=1}^{N} a_i.\]Here, (n_i) denotes the point count of the (i)-th pose-estimate sample, and (a_i) denotes its anisotropy ratio. Therefore, (\bar{n}) is the mean point count over the history window, and (\bar{a}) is the mean anisotropy ratio over the same window.
These quantities are converted into bounded component scores:
\[S_p = \frac{1}{1+\sigma_p^2/\eta_p}, \qquad \eta_p = 0.005,\] \[S_\psi = \frac{1}{1+\sigma_\psi^2/\eta_\psi}, \qquad \eta_\psi = 0.08,\] \[S_n = \operatorname{clip}\left(\frac{\bar{n}}{\eta_n}, 0, 1\right), \qquad \eta_n = 200,\] \[S_a = \operatorname{clip}\left(\frac{\bar{a}}{\eta_a}, 0, 1\right), \qquad \eta_a = 0.5.\]The final confidence score is
\[C_k = w_p S_p + w_\psi S_\psi + w_n S_n + w_a S_a,\]where the current implementation uses
\[w_p = 0.3,\qquad w_\psi = 0.2,\qquad w_n = 0.1,\qquad w_a = 0.15.\]The orchestrator stops active perception if
\[N \geq N_{\min} \quad \text{and} \quad C_k \geq \tau,\]otherwise it requests a next-best-view.
\[N_{\min} = 10\]in the current implementation.
For next-best-view planning, let the candidate viewpoint set be
\[\mathcal{V} = \{v_i\}_{i=1}^{M},\]where each (v_i) is a candidate robot observation pose generated around the current target estimate. Each candidate is then scored by
\[J(v_i)= \alpha \frac{|r_i-r_d|}{r_d} + \beta \frac{d_i}{r_{\max}} + \gamma \frac{|\operatorname{wrap}(\theta_i-\theta_k)|}{\pi},\]In this cost function, (r_i) denotes the candidate radius from the target, (r_d) denotes the desired observation radius, (d_i) denotes the robot travel distance from its current pose to the candidate, and (\theta_i) denotes the candidate viewing yaw. The term (\theta_k) denotes the robot’s current yaw in the planning frame. The planner then selects
\[v_k^\star = \arg\min_{v_i \in \mathcal{V}_{\text{valid}}} J(v_i),\]after rejecting candidates whose travel distance is below a minimum threshold. The current implementation uses
\[\alpha = 0.2,\qquad \beta = 0.1,\qquad \gamma = 0.2.\]When radius randomization is enabled, each candidate radius is sampled in the interval ([r_{\min}, r_{\max}]); otherwise a fixed or adaptive base radius is used.
3. Benchmarking & Results
3.1 Experimental Setup
The experimental platform is a TurtleBot4 operating in an indoor environment using an RGB-D / stereo sensing stack together with local odometry and visual-odometry-based localization. The active perception pipeline was evaluated on target objects including a box and a cylinder, with all perception, planning, and motion execution expressed in the local odom frame rather than a global map frame. Each trial began from a reset local reference by calling the odometry reset service so that odom returned to zero before data collection. A successful run was defined as detecting the target, estimating its pose, and either reaching a sufficiently confident final estimate or triggering viewpoint updates when confidence remained low.
3.2 Experimental Results
The main input to the system is the raw point cloud, and obtaining this data stream reliably was the most time-consuming hardware and integration challenge of the project. The system required raw point clouds for box and cylinder detection, while the visual odometry module simultaneously required synchronized left and right camera streams. After extensive testing with multiple configurations, we established a workable pipeline by streaming RGB and depth data in compressed form and at reduced image resolution. The compressed image streams were decompressed on the external PC using the image_transport package, and raw point clouds were then reconstructed on the PC using depth_image_proc before being passed to the perception nodes.
Although this configuration provided the best overall solution, the networked sensor pipeline remained unreliable. In practice, the RGB, depth, and stereo camera streams were not always published consistently, which significantly limited the ability to execute trials in a repeatable and stable manner.
When the required data streams were available, however, the perception and planning pipeline operated as intended. The perception module successfully detected the brown box, the pose estimator computed the target pose and transformed it into the odom frame, and the confidence evaluator was triggered after collecting 10 pose samples. When the confidence score remained below the specified threshold, the system correctly requested a next-best-view update. The NBV planner then generated candidate viewpoints and selected the best one according to the implemented cost function. Overall, the perception and planning modules behaved reliably given valid incoming data. Figure 2 shows a representative system snapshot after a next-best-view had been generated.
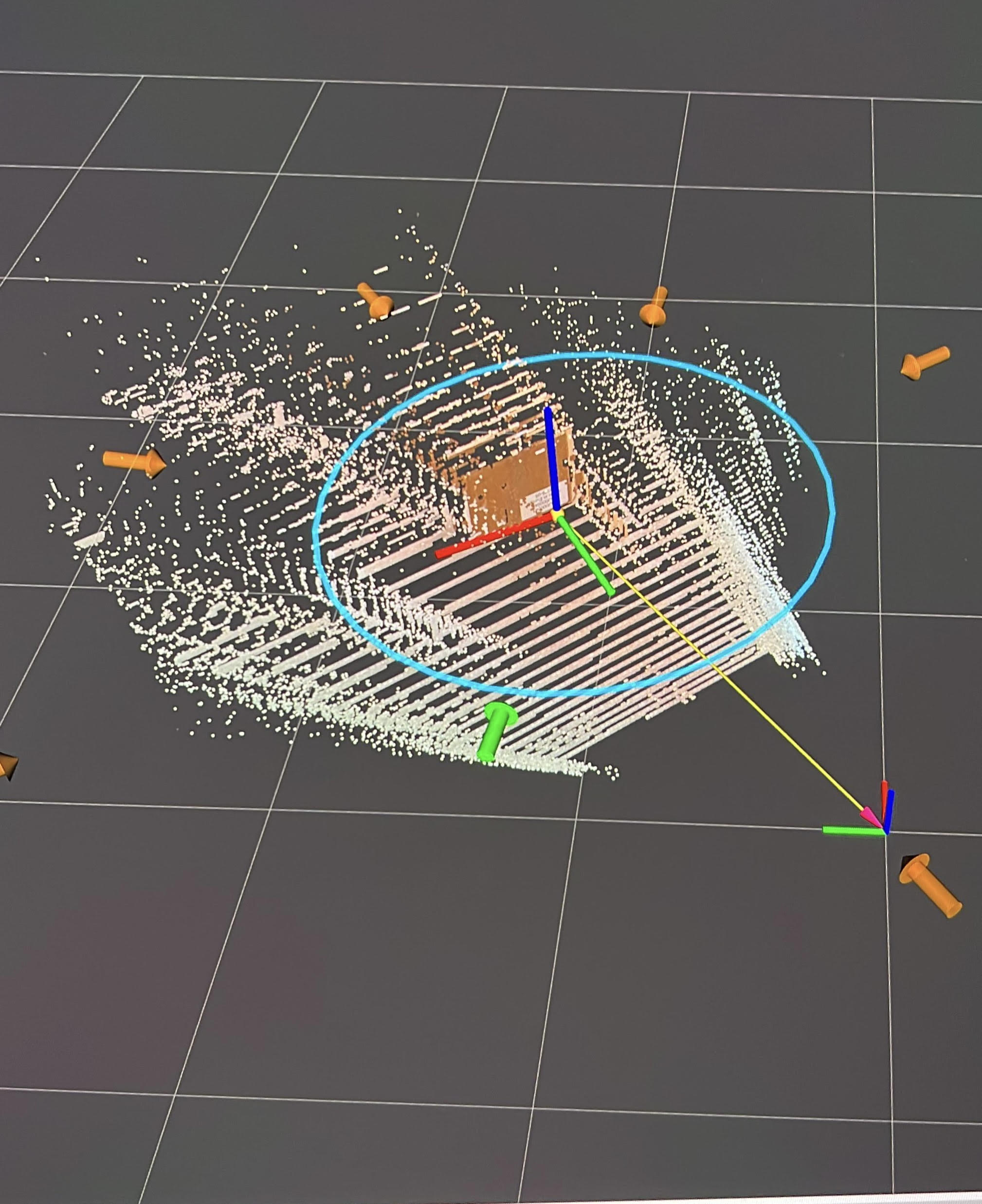
Figure 2. System Snapshot after a Next-Best-View had been Generated.
A second major challenge arose during system integration, specifically in the navigation and control module. As discussed earlier, Nav2 assumes the availability of a map, and our attempts to bypass this requirement by running slam_toolbox concurrently were not successful. As a result, we replaced the original navigation plan with a lightweight PD-based local controller that drives the robot to the selected goal pose directly in the odom frame.
This substitution enabled local motion execution and allowed the closed-loop pipeline to continue operating without a global map. However, system-level trials revealed a remaining limitation: although the TurtleBot4 moved toward the selected next-best-view position, its final orientation at the goal did not fully align with the desired NBV pose. This behavior can be observed in the full demo video below. Due to time constraints near the end of the semester, this issue was not fully resolved in the final implementation
3.2.1 Demo Links
Perception & Planning Demo :https://youtu.be/uHptjgO3Q7YFull System Demo :https://youtu.be/R4nFs0lb5PI
3.3 Discussion of Results
The ROS bag comparison between visual odometry (VO) and wheel odometry (/odom) shows strong agreement in the straight segment and larger divergence in the curved/loop segment.
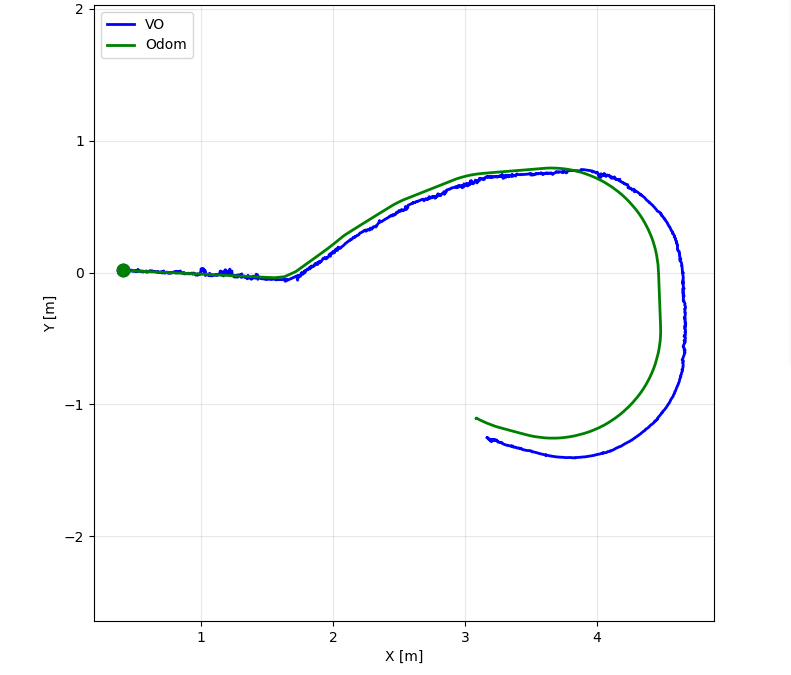
Figure 3. VO (/orb_slam/vo_path, blue) vs wheel odometry (/odom, green) trajectory comparison from ROS bag playback.
| Path Segment | VO | Odom |
|---|---|---|
| Straight path | Closely follows odom trend with small jitter; good startup alignment. | Smooth baseline trajectory with low short-horizon drift. |
| Curved path | Tracks loop shape but drifts outward and accumulates larger offset. | Tighter and smoother loop estimate compared to VO. |
Estimated position error values from the VO-vs-odom error plot (2127 samples):
| Segment | Approx. Time Window | Error Range (m) | Representative Error (m) | Peak Error (m) |
|---|---|---|---|---|
| Straight path | 0-30 s | 0.00-0.09 | ~0.05 | ~0.09 |
| Curved path | 30-70 s | 0.09-0.24 | ~0.18 | ~0.24 |
Interpretation:
- Straight motion remains well aligned, confirming that the VO pipeline is stable for low-curvature motion.
- Error grows mainly during long curved motion, indicating accumulated drift and heading sensitivity.
- This matches the localization risk identified earlier: synchronization quality and long-horizon drift dominate final accuracy.
4. Ethical Impact Statement
This project combines perception, localization, and autonomous motion (odom-frame local navigation) to improve object pose estimation through active viewpoint selection. Because the robot uses RGB-D sensing and moves near people/obstacles, ethical analysis is required at both micro-ethics (engineering decisions in implementation) and macro-ethics (system effects on users and bystanders).
4.1 Ethics Scorecard (Formal Tests)
| Test | Status | Reasoning (Cite Part 1 Definitions) |
|---|---|---|
| Utilitarian Test | Pass (Conditional) | The active-perception loop improves mission success (better object localization) and reduces repeated manual intervention, which creates clear operational benefit. However, benefit depends on safe execution and sensor reliability; if localization degrades, utility drops quickly. |
| Justice Test | Partial / Needs Improvement | The system does not intentionally classify people by sensitive attributes, but fairness is not yet formally audited across lighting, texture, object material, and occlusion conditions. Uneven error rates across environments can create unequal burden (e.g., poorer performance in cluttered or reflective scenes). |
| Virtue Test | Pass (Conditional) | The implementation shows responsible engineering intent: explicit safety monitoring, conservative goal execution, and transparent module traceability. Remaining virtue gap: incomplete quantitative safety/fairness validation before claiming production readiness. |
4.2 Privacy
The robot consumes camera streams and point clouds that can incidentally capture people in indoor environments. In the current pipeline, data is primarily used for online processing (feature extraction, stereo matching, VO/path estimation) rather than identity analytics. No face recognition or person re-identification is implemented. Ethical risk remains if raw recordings are stored or shared without policy controls. Recommended practice is data minimization: store only what is needed for debugging, limit retention duration, and remove personal imagery from public artifacts.
4.3 Safety
The dominant ethical risk is physical harm from autonomous motion. This project addresses safety through bounded local control, odom-frame goal execution, and stop-oriented behavior when sensing/localization quality is poor. Safety intent is consistent with the project scope in Reports 1 and 2: avoid unsafe continuation under stale or unreliable state estimates. Residual risk remains in edge cases such as dynamic obstacles, abrupt VO degradation, and timing mismatch between sensing and actuation. Therefore, conservative velocity bounds and robust stop conditions are ethically required, not optional.
4.4 Bias and Technical Limitations
Perception quality depends strongly on texture, illumination, synchronization quality, and geometric visibility. ORB-based VO and stereo depth can underperform in low-texture scenes, glare, blur, and partial occlusion. This is a technical bias source: performance is not uniform across all operating contexts. If unreported, this can create misleading trust in autonomy. Ethical reporting therefore requires explicit disclosure of known failure modes and quantitative error ranges.
4.5 Ethical Framework Interpretation and Engineering Fixes
From a utilitarian view, the system is justified when total safety and task benefit exceed deployment risk. From a justice view, fairness requires validation across diverse scenes and operating conditions, not only nominal runs. From a virtue view, engineers should prioritize transparent limitations and fail-safe behavior over optimistic claims.
Immediate engineering fixes:
- Add a formal pre-deployment checklist with localization confidence and sensor-freshness gates before motion authorization.
- Add fairness-style robustness tests across at least multiple lighting/texture/object conditions and report per-condition failure rates.
- Add strict data-handling policy for camera recordings (retention limit and anonymization for shared media).
5. Custom Module Code Links
Every custom module discussed in this report must include a direct repository hyperlink to the relevant source file and, where possible, the exact line range implementing the logic.
| Module | Role in System | Direct Link |
|---|---|---|
cylinder_finder.py | Cylinder detection from point clouds | cylinder_finder.py |
box_finder.py | Box detection from point clouds | box_finder.py |
pose_estimator.py | Pose estimation in the planning frame | pose_estimator.py |
confidence_evaluator.py | Confidence scoring service | confidence_evaluator.py |
nbv_planner.py | Next-best-view planning | nbv_planner.py |
orchestrator.py | Active perception coordination | orchestrator.py |
odom_controller.py | Local odom-frame navigation controller | odom_controller.py |
orb_vo.yaml | Localization configuration | orb_vo.yaml |
orb_vo_node.py | Visual odometry integration | orb_vo_node.py |
ekf.yaml | Sensor fusion configuration | ekf.yaml |
6. Individual Contribution & Audit Appendix
This appendix should make authorship auditable and match the Milestone 3 requirement for individual technical accountability.
| Team Member | Primary Technical Role | Key Git Commits / PRs | Specific File(s) Authorship |
|---|---|---|---|
| Mohammad Nasr | Perception & Planning Module | 970c915, b180cfd, 4a9a162, 03b2bf6 | cylinder_finder.py, box_finder.py, pose_estimator.py, confidence_evaluator.py, nbv_planner.py, orchestrator.py, odom_controller.py |
| Vikas Narang | Localization_Module (VO + EKF) | 1 parent 3b519bc, 61fc196 (report contribution), ORB_EKF commits | src/ORB_EKF/orb_ekf/orb_vo_node.py, src/ORB_EKF/config/orb_vo.yaml, src/ORB_EKF/config/ekf.yaml |
| Khaled | Navigation_Module | e5e9469 | navigation subsystem design and Nav2 integration artifacts |